Next: Overlapping tiles Up: Distinctive Image Features from Previous: Distinctive Image Features from Contents Index
Orientation and gradient assignment
We start with orientation ![]() and gradient
and gradient ![]() assignment for every pixel
assignment for every pixel ![]() in sample image
in sample image ![]() .
Let
.
Let ![]() is a pixel intensity at position
is a pixel intensity at position ![]() in image
in image ![]() :
:
We would like to obtain the same features for image (a) and (b) in figure 3.6 on page ![]() . We need this this
result since we want to cope with various metal surface colors from dark colors to bright colors. This is
the reason we assign to
. We need this this
result since we want to cope with various metal surface colors from dark colors to bright colors. This is
the reason we assign to ![]() the orientation modulo
the orientation modulo ![]() :
:
The local image descriptor representations
The previous orientations have assigned an orientation and gradient for every pixel in the image. The next step is to compute the descriptor which is distinctive yet is as invariant as possible to parameters such as change in illumination, shift in vertical or horizontal direction or viewpoint change. One usual approach would be to sample local image intensities around the keypoint at appropriate scale and to match these using a normalized correlation measure. However, simple correlation of image patches is highly sensitive to changes that cause misregistration of samples, such as affine or 3D viewpoint change.
As we can see on figure 3.7 on page ![]() the image is divided into several square patches (tiles). Every square
patch is divided into certain number of bins. Every bin represents a certain interval of orientations which are
assigned to it. We call this interval a direction. We can number bins from
the image is divided into several square patches (tiles). Every square
patch is divided into certain number of bins. Every bin represents a certain interval of orientations which are
assigned to it. We call this interval a direction. We can number bins from ![]() to
to ![]() , where
, where ![]() is
the number of bins for each tile (i.e. number of directions for each tile).
Similarly we can number tiles from
is
the number of bins for each tile (i.e. number of directions for each tile).
Similarly we can number tiles from ![]() to
to ![]() , where
, where ![]() is the number of tiles.
is the number of tiles.
How the values are assigned to every bin depends on the SIFT representation. We proposed 3 variants:
SIFT-Ori
This is the easiest representation. Every orientation has the same vote, which equals to one.
Given the ![]() -th tile
-th tile ![]() we can compute values for every
we can compute values for every ![]() -th bin as:
-th bin as:
where ![]() ranges from
ranges from ![]() to
to ![]() .
.
With this approach we can have problems when there is the same probability for the direction in the tile. This can apply for random texture but also for circle-like shapes. If we want to distinguish between these two cases we should use votes based on gradient magnitude (SIFT-Grad).
SIFT-Grad
This can be more distinctive between the random textures and circle-like shapes
(figure 3.8 on page ![]() ). Random textures have usually small local gradients. We can use this
information to achieve the similar result as displayed in the picture. We do not want the histograms
to be the same (as they would be when each direction has the same vote weight). We can choose the
vote weight correlated to the gradient magnitude. Given a tile
). Random textures have usually small local gradients. We can use this
information to achieve the similar result as displayed in the picture. We do not want the histograms
to be the same (as they would be when each direction has the same vote weight). We can choose the
vote weight correlated to the gradient magnitude. Given a tile ![]() we have:
we have:
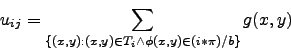
SIFT-GradWei
This representation can deal better with shifts of the tile. Given the ![]() -th tile
-th tile ![]() and
and
![]() ,
, ![]() is the center of the tile:
is the center of the tile:
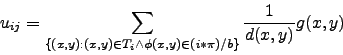
where ![]() is computed as:
is computed as:
![]() is the distance of point
is the distance of point ![]() from the center.
from the center.
![\includegraphics[width=80mm,height=40mm]{oripi.eps}](img77.png)
![\includegraphics[width=80mm,height=40.3mm]{fve.eps}](img80.png)
![\includegraphics[width=80mm,height=30mm]{circle_texture.eps}](img86.png)